1.0 Introduction: Why MLOps is the Foundation of Enterprise AI
Machine Learning Operations (MLOps) is a discipline that applies the principles of software engineering and DevOps to the machine learning (ML) lifecycle. It establishes a set of best practices for unifying the development, deployment, and management of ML models in production environments.
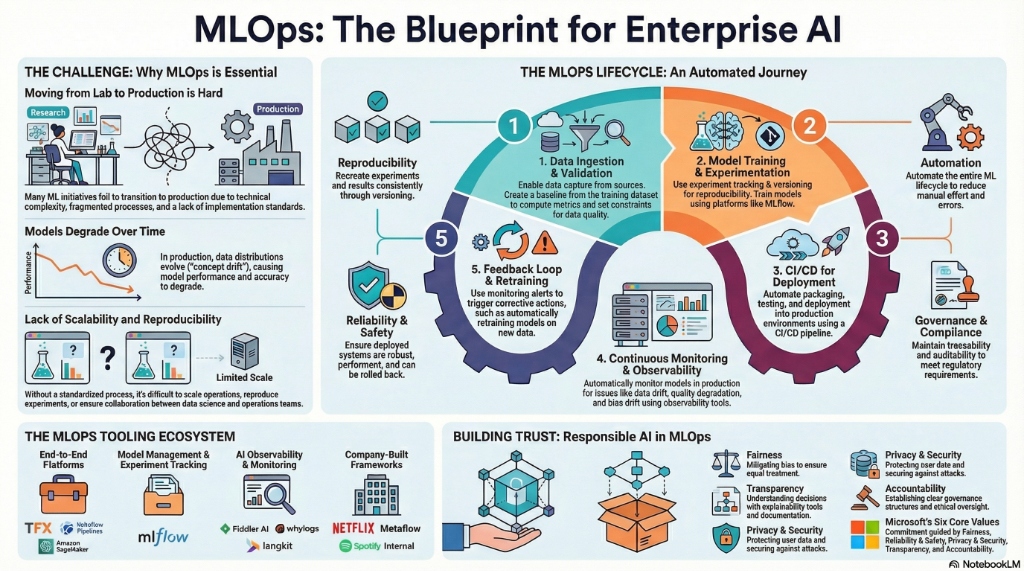
The adoption of MLOps has become critical for modern enterprises seeking to scale their artificial intelligence (AI) initiatives. While many organizations can successfully develop ML models, operationalizing them presents substantial challenges. These include issues with scalability, ongoing maintenance, coordination across teams, fragmented tooling, and complex data management. Without a systematic MLOps framework, a staggering number of AI projects fail to transition beyond the prototype stage, trapping their potential business value in isolated experiments. This failure to launch is the central problem MLOps is designed to solve.
This report serves as a comprehensive guide to MLOps principles, best practices, and a strategic roadmap for enterprise adoption. It is designed for both technical and business leaders, providing the insights needed to build a robust foundation for scaling AI responsibly and effectively, and to finally bridge the gap between AI promise and production reality.
2.0 The Core Challenge: Bridging the Gap Between ML Development and Operations
A fundamental disconnect exists between traditional ML model development and the operational demands of production systems. This distinction is critical because it sits at the heart of why so many AI projects fail. ML development is often experimental and research-focused, prioritizing the discovery of predictive patterns. In contrast, ML operations require reliability, scalability, and consistent performance in a live environment. Operationalizing a model transforms it from a static piece of code into a dynamic system that must be continuously managed and maintained.
Enterprises commonly face the following challenges when attempting to bridge this gap:
- Data Manipulation: Ensuring consistent data quality, preprocessing, and feature engineering across training and inference pipelines is a significant hurdle.
- Model Building: The lack of standardized processes for model training, versioning, and validation leads to reproducibility issues and inconsistent results.
- Deployment Pipelines: Difficulties in automating the deployment process result in slow, error-prone, and manual handoffs between data science and operations teams.
- Industrial Integration: Integrating MLOps practices into established industrial Operational Technology (OT) environments, such as manufacturing, presents unique obstacles related to legacy systems and real-time constraints.
These challenges are not merely technical hurdles; they represent fundamental organizational friction. Without a cross-functional MLOps strategy, the value of even the most predictive models remains trapped in a data scientist's notebook.
MLOps: The Blueprint for Enterprise AI - Lifecycle, Challenges, and Best Practices
3.0 The MLOps Lifecycle: An End-to-End Framework
A mature MLOps practice orchestrates the entire machine learning lifecycle through a sequence of automated stages, ensuring a continuous and reliable flow from data ingestion to model improvement. This framework can be broken down into five key stages.
Data Operations
This stage focuses on the automated ingestion, validation, and preparation of data for model training. The goal is to ensure that high-quality, consistent data is available throughout the lifecycle. Key activities include automated data validation to check for schema anomalies and statistical properties, ensuring that the data meets predefined expectations before it is used for training.
Model Training & Experimentation
Here, the focus is on systematically training, evaluating, and tracking model experiments. This stage includes experiment tracking to log parameters, metrics, and artifacts for each training run, as well as model packaging to ensure that trained models are bundled with their dependencies for reproducible deployments.
Deployment
This stage involves packaging the validated model and deploying it into a production environment where it can serve predictions. It relies on CI/CD (Continuous Integration/Continuous Deployment) orchestration to automate the build, test, and release process. Deployed models are often served via scalable platforms like TensorFlow Serving, which are optimized for high-performance inference.
Monitoring
Once a model is in production, it must be continuously monitored to detect degradation in performance. This includes monitoring for drift in data quality, model quality metrics (like accuracy), and feature importance. Proactive detection of these deviations enables timely corrective actions.
Governance & Feedback
The final stage establishes a feedback loop to drive continuous improvement and ensure compliance. Monitoring systems can be configured with retraining triggers that automatically initiate a new training pipeline when model performance degrades below a certain threshold. This ensures the ML system adapts to changing data patterns and maintains its effectiveness over time.
4.0 Core Pillars of a Mature MLOps Practice
A successful MLOps strategy is built on a foundation of core principles that directly address the challenges of operationalizing AI. These pillars ensure the entire ML lifecycle is robust, efficient, and trustworthy.
- Reproducibility: The ability to reproduce experiments and model outcomes is critical for debugging, auditing, and building upon previous work. Research shows a significant positive relationship between reproducibility and user satisfaction.
- Automation: Automation is the engine of MLOps, eliminating manual handoffs and reducing the risk of human error. It is achieved through CI/CD pipelines and workflow orchestration, which automate the entire process from data validation and model training to deployment and monitoring.
- Reliability & Safety: ML systems, especially those in critical applications, must perform reliably and safely. This pillar emphasizes the need for robust testing, validation, and continuous monitoring to ensure the system operates as intended and does not cause harm.
- Governance: Governance involves managing and controlling the ML lifecycle to ensure compliance with regulatory requirements, ethical standards, and organizational policies. The emergence of concepts like "Regulatory Operations (RegOps)" highlights the growing need to operationalize compliance within the MLOps framework.
- CI/CD for ML: Continuous Integration and Continuous Deployment (CI/CD) for ML is the mechanism that enables the continuous evolution of ML systems. Unlike traditional software, ML systems degrade over time due to concept drift. CI/CD pipelines automate the retraining and redeployment of models to adapt to new data.
5.0 The MLOps Tooling Landscape
The MLOps landscape is composed of a diverse set of tools, both open-source and commercial, that address specific needs across the ML lifecycle. The tooling landscape reflects the maturity of the MLOps space. While end-to-end platforms offer a unified experience, the proliferation of specialized tools for monitoring and observability indicates that visibility into production models remains a critical and complex challenge.
| Tool Category | Examples |
|---|---|
| End-to-End Platforms | TFX (TensorFlow Extended), Kubeflow Pipelines |
| Experiment Tracking & Model Registry | MLflow |
| Model Monitoring & Observability | Amazon SageMaker Model Monitor, Fiddler AI, whylogs, langkit (from WhyLabs) |
| Developer Experience | Spotify's Backstage |
6.0 Enterprise-Grade MLOps: A Guide to Best Practices
With the foundational pillars established, we now turn to the specific, tactical best practices required to implement them effectively and mitigate production risks.
6.1 Implement Continuous Monitoring and Observability
Continuous monitoring is essential for detecting and mitigating model performance degradation. A comprehensive monitoring strategy tracks several types of drift:
- Data Quality Drift: Detects changes in the statistical properties of incoming data compared to the training data.
- Model Quality Drift: Monitors for degradation in model performance metrics, such as accuracy or precision.
- Bias Drift: Tracks changes in bias in a model's predictions across different demographic groups.
- Feature Attribution Drift: Monitors for shifts in the relative importance of input features over time.
6.2 Implement an Efficient Retraining Strategy
ML models are not static; their performance degrades over time due to "concept drift," where the statistical properties of the target variable change. A key best practice is to establish an efficient model maintenance strategy. Instead of frequent, resource-intensive retraining, a more advanced approach is to identify recurrent data distributions. By reusing previously trained models that are well-suited for these recurring patterns, organizations can maintain high performance while significantly reducing the time, cost, and computational resources associated with unnecessary retraining cycles.
6.3 Embed Security into Every Lifecycle Stage
Securing MLOps pipelines is increasingly critical as ML models become integral to business operations. A single misconfiguration can lead to compromised credentials, severe financial losses, damaged public trust, and the poisoning of training data. A systematic approach to secure MLOps involves mapping adversarial threats to each phase of the ML lifecycle. Frameworks like the MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems) provide a comprehensive catalog of AI-focused attacks.
6.4 Operationalize Governance and Compliance
With the rise of regulations like the EU AI Act, MLOps must evolve to support governance and compliance requirements. This involves creating transparent, auditable ML workflows. AI Observability platforms like Fiddler provide unified observability with dashboards for metrics, root cause analysis, and audit evidence for governance. This helps organizations demonstrate compliance with internal policies and external regulations.
7.0 Comparing Cloud-Native MLOps Approaches
Major cloud providers offer managed services to simplify the implementation of MLOps.
7.1 Amazon Web Services (AWS)
AWS provides Amazon SageMaker Model Monitor, a comprehensive solution for monitoring ML models in production. It automatically monitors models deployed on real-time endpoints or used in batch transform jobs. The process involves enabling data capture, creating a baseline from the training dataset, scheduling monitoring jobs, and inspecting reports that compare the latest data against the baseline.
7.2 Microsoft Azure
Microsoft's approach emphasizes Responsible AI. Microsoft is committed to designing, building, and releasing AI technologies guided by core principles of fairness, reliability, safety, and transparency. Microsoft provides tools within the Azure AI platform to support organizations in implementing responsible AI innovation.
8.0 MLOps in Action: Industry Case Studies
Leading technology companies have pioneered many of the MLOps practices in use today.
8.1 Netflix
Netflix focuses heavily on supercharging the ML/AI developer experience and ensuring ML observability. They utilize tools like Metaflow to accelerate development and enable notebook-like iteration within production-ready workflows. Their work on the "Maestro" workflow engine and on ML observability aims to bring transparency and efficiency to complex systems across the business.
8.2 Spotify
Spotify has invested in building robust experimentation platforms, referred to as their "Learning Framework," to scale product decision-making. They have also developed and open-sourced Backstage, a platform for building developer portals that improves developer productivity. Spotify uses TFX to build and manage its production ML pipelines.
8.3 Other Examples
The TFX end-to-end platform is used in production by other major companies, including Airbus, Gmail, and OpenX.
9.0 Integrating Ethical and Responsible AI into MLOps
A mature MLOps practice must go beyond technical efficiency to incorporate ethical principles. Microsoft's Responsible AI framework provides six core values:
- Fairness: AI systems should treat all people fairly. MLOps pipelines should include steps to assess and mitigate bias in datasets and models.
- Reliability and safety: AI systems should perform reliably and safely through rigorous testing, validation, and continuous monitoring.
- Privacy and security: AI systems must be secure and respect privacy with proper data handling and access controls.
- Inclusiveness: AI systems should empower everyone and engage people, designing systems that are accessible and beneficial to diverse populations.
- Transparency: AI systems should be understandable with proper documentation, explanations, and visualizations.
- Accountability: People should be accountable for AI systems with clear lines of ownership and governance structures.
10.0 Building an MLOps-Ready Organization
Successfully adopting MLOps requires a significant organizational and cultural shift. A strategic framework can be structured around five key pillars:
- Leadership & Strategy: Executive leadership must champion a clear, organization-wide AI strategy that aligns technical goals with business objectives.
- MLOps & Technical Infrastructure: Invest in building a scalable and standardized technical infrastructure that supports the entire MLOps lifecycle.
- Governance & Ethics: Establish a formal governance structure to oversee AI development and ensure ethical standards.
- Education & Workforce Development: Invest in training and upskilling the workforce to bridge skill gaps and foster a data-literate culture.
- Change Management & Adoption: Implement a deliberate change management process to drive adoption of new tools and workflows.
11.0 An Enterprise Roadmap for Adopting MLOps
Enterprises can adopt MLOps progressively through a three-stage roadmap:
Stage 1: Foundational (Manual Processes & Foundational Tooling)
This initial stage is characterized by largely manual and siloed processes. The primary focus is on establishing basic best practices, such as using version control for code and implementing experiment tracking tools like MLflow to log and compare model training runs.
Stage 2: Automated Pipelines (CI/CD for ML)
In this stage, the organization begins to automate the ML pipeline. This involves implementing end-to-end pipeline orchestration tools like TFX or Kubeflow Pipelines and establishing a CI/CD system for continuous model training and deployment.
Stage 3: Optimized and Governed Operations (Advanced MLOps)
This represents a mature MLOps practice with comprehensive and continuous monitoring for data, model, and bias drift. This stage is defined by robust governance, integrated security, and a culture of continuous improvement and responsible AI.
12.0 Conclusion: Actionable Recommendations for Scaling ML Responsibly
MLOps is no longer an optional discipline for advanced tech companies; it is the essential foundation for any enterprise that wants to successfully scale its AI initiatives and generate real business value. By moving from manual, ad-hoc processes to an automated, reliable, and governed lifecycle, organizations can accelerate innovation while managing risk.
For enterprise leaders, the path forward includes:
- Start with Governance to Build Trust: Implement a responsible AI framework based on principles like fairness and transparency from the outset.
- Automate Incrementally to Overcome Silos: Target fragmented deployment pipelines first by automating model packaging and deployment.
- Invest in Observability to Manage Risk: Prioritize robust monitoring and observability tools to detect and diagnose model degradation quickly.
- Foster an MLOps Culture for Lasting Change: Recognize that MLOps is as much about people and processes as it is about technology.