1.0 Introduction: The Data-Driven Promise and the Pipeline Problem
In today's competitive landscape, the aspiration to be "data-driven" is universal. Every organization wants to harness its data to augment and improve every aspect of its business. Yet, the reality for many is a constant struggle with continuously failing ETL jobs and the profound divide between the operational data that runs the business and the analytical data that should be informing its future. This divergence creates a fragile architecture, where a labyrinth of complex pipelines often fails to deliver reliable, timely insights.
Overcoming this challenge is no longer a niche technical concern; it is a strategic imperative. The data pipeline is not merely a piece of infrastructure but the central nervous system of a modern, intelligent enterprise. It is the conduit that transforms raw operational facts into the actionable intelligence that fuels innovation, efficiency, and competitive advantage.
To bridge this divide, businesses must embrace a new way of thinking about how data flows through the organization. The solution lies in building robust, scalable data pipelines. A data pipeline, at its core, is the process that unlocks the value hidden within your data, making the data-driven promise a reality.
2.0 What is a Data Pipeline? Your Business's Digital Supply Chain
At its simplest, a data pipeline is your business's digital supply chain. Just as a physical supply chain sources raw materials, processes them in a factory, and delivers a finished product to consumers, a data pipeline ingests raw data, transforms it, and serves refined insights to business users, analysts, and applications. This process ensures that the right data is in the right place, in the right format, at the right time.
The core process can be visualized in three distinct stages:
- Stage 1: Ingestion (Sourcing Raw Materials) - This is the starting point, where raw data is collected from a multitude of sources. These can include transactional databases that power your applications, event streams from websites, data from third-party partners, and more.
- Stage 2: Processing (The Factory Floor) - Once ingested, the raw data enters the transformation stage. Here, it is cleaned, standardized, enriched, and aggregated to prepare it for analysis. This step typically follows one of two patterns: ETL (Extract, Transform, Load), a traditional approach ideal for structured, predictable reporting where data is cleaned before entering a central warehouse, or ELT (Extract, Load, Transform), a modern, more flexible approach where raw data is loaded into a data lake first and transformed later, enabling a wider variety of analytics and data science use cases.
- Stage 3: Serving (Delivery to Consumers) - In the final stage, the processed, high-quality data is made available to its end users. This "finished product" can be served to business intelligence (BI) dashboards, used for ad-hoc analytics, or fed into machine learning models to generate predictions and power intelligent applications.
Having a functional pipeline is the first step, but for a modern business to thrive, that digital supply chain must be built to handle growth, complexity, and rapid change. It must be scalable.
3.0 Why Scalability Matters: Moving from Fragile Infrastructure to Agile Innovation
Traditional, rigid data architectures inevitably fail at scale. They were not designed to handle the modern data landscape, which is defined by a "proliferation of sources of data," constant "changes in the data landscape," and an ever-growing "diversity of data use cases." This results in a centralized, monolithic system that becomes a bottleneck, creating brittle digital supply chains riddled with high friction and failing jobs.
The business consequences of a non-scalable pipeline are severe, hindering growth and stifling innovation. Conversely, a modern, scalable pipeline creates immense value by fostering agility and data-driven decision-making across the organization.
The Cost of a Brittle Pipeline vs. The Value of a Scalable One
| Brittle Pipeline (The Past) | Scalable Pipeline (The Future) |
|---|---|
| High friction and cost of discovering and using data. | Data is treated as a product: discoverable, understandable, and trustworthy. |
| Ever-growing complexity and continuously failing jobs. | Autonomous teams can innovate independently and quickly. |
| Centralized bottlenecks that slow down the business. | Decentralized ownership that speeds up response to change. |
| Inability to support modern AI and analytics. | A foundation for getting value from AI and historical facts at scale. |
To achieve this future state, organizations must adopt new architectural paradigms designed from the ground up for agility and scale. The most prominent of these is the Data Mesh.
4.0 The Modern Blueprint: Key Principles of a Scalable Data Architecture
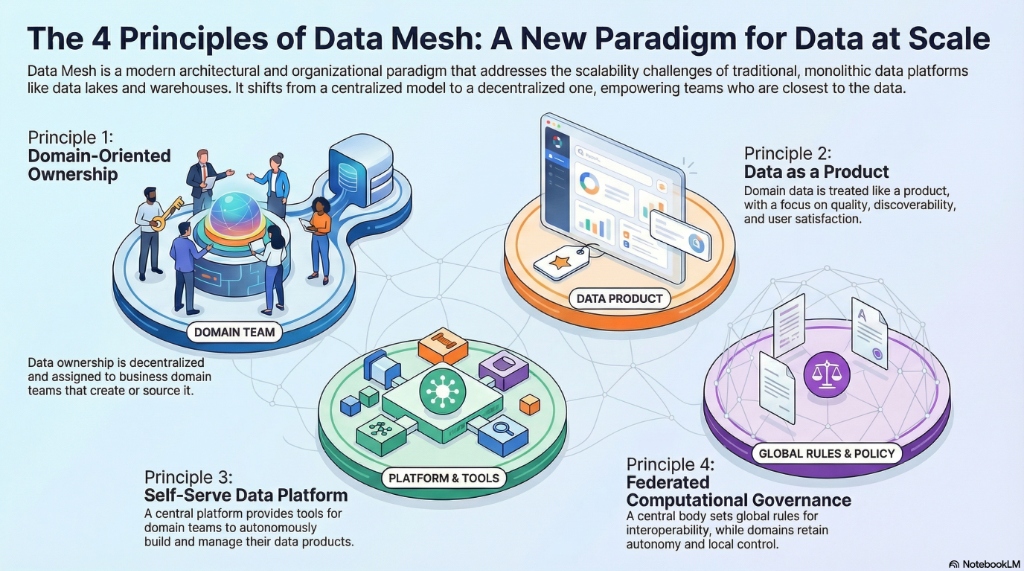
The Data Mesh is not a technology but a paradigm shift in organizational and technical thinking. It inverts the traditional, centralized model of data management by building on four core principles. This approach decentralizes data ownership and empowers teams to move faster while ensuring the entire data ecosystem remains connected, secure, and interoperable.
The 4 Principles of Data Mesh: A New Paradigm for Data at Scale
Domain Ownership
The Principle: This principle decentralizes the responsibility for analytical data, moving it away from a central data team and giving it to the business domains that are closest to the data. Think of it as giving each business department—like sales, marketing, or logistics—full ownership and responsibility for their own part of the digital supply chain, from source to consumer.
Business Impact: This shifts accountability for data quality upstream, improving it at its source. It empowers the people who best understand the data's context and meaning to manage it, which accelerates response times to business changes and reduces the burden on a central team.
Data as a Product
The Principle: This principle dictates that the data shared by a domain should be treated as a product, with its users treated as customers. This means the data must be discoverable, understandable, trustworthy, secure, and accessible. Each "data product" has a dedicated owner responsible for its quality and usability.
Business Impact: Treating data as a product directly addresses the high friction and cost associated with finding and trusting data. It transforms data from a technical byproduct into a reliable, high-quality asset that internal teams can confidently use to make decisions and build new capabilities. In short, this principle eradicates the hidden tax of "data wrangling" that consumes up to 80% of an analyst's time.
Self-Serve Data Platform
The Principle: To enable domain teams to manage their own data products autonomously, they need access to a common platform that provides the necessary tools and infrastructure as a self-service. This platform handles the underlying technical complexity of data storage, pipeline orchestration, monitoring, and security, allowing domain teams to focus on creating value.
Business Impact: A self-serve platform dramatically lowers the cost and specialized knowledge needed to build and maintain data pipelines. It provides domain teams with the autonomy to innovate quickly without being blocked by infrastructure requests, leading to faster delivery of data products.
Federated Governance
The Principle: While domains operate autonomously, the data ecosystem needs a set of global rules to ensure all data products can interoperate. Federated governance establishes a model where domain representatives and platform owners collaborate to define global standards for security, interoperability, and quality. These rules are then automated and embedded into the self-serve platform.
Business Impact: This model maintains an equilibrium between domain autonomy and global interoperability. It prevents the creation of incompatible data silos while avoiding the bottlenecks of centralized governance. By ensuring all data products adhere to common standards, it creates a "compounding network effect," where the value of the ecosystem grows as more data products are added and combined.
Adopting these architectural principles is not just a theoretical exercise; it generates clear, measurable business outcomes.
5.0 The Tangible Returns: Analyzing the ROI of a Modern Data Pipeline
Modernizing data infrastructure is not a cost center; it is a direct driver of business performance, operational efficiency, and sustained competitive advantage. The return on investment (ROI) is evident in accelerated performance, reduced costs, and enhanced capabilities that directly impact the bottom line.
Recent benchmarks and case studies highlight the significant quantitative gains organizations can achieve:
- Dramatic Performance Acceleration: Modern data platforms can dramatically speed up analytical workloads. For example, Amazon EMR can make Apache Spark and Iceberg workloads up to 4.5x faster than open-source equivalents. Similarly, Amazon Redshift delivered over a twofold query performance improvement for data lake workloads, enabling faster insights from massive datasets.
- Significant Cost Reduction: Migrating from legacy or complex self-managed systems to modern, managed services can yield substantial savings. The company Octus, for instance, achieved an 85% infrastructure cost reduction by migrating its workloads to a modern service, freeing up capital for other strategic investments.
- Enhanced Operational Efficiency: A scalable data architecture empowers organizations to handle complex, mission-critical operations at scale. Medidata created a "unified, scalable, real-time data platform" on modern architecture to effectively serve thousands of clinical trials worldwide. This demonstrates how a Self-Serve Platform and Data as a Product thinking can drive operational excellence at a global scale.
These quantitative returns are not abstract; they are the direct result of specific architectural choices made by industry leaders, as we will now explore.
6.0 In Action: How Industry Leaders Power Their Business with Data
Leading technology companies do not view their data architecture as a back-office function; they treat it as a core product differentiator that powers everything from user experience to operational excellence. Their highly optimized digital supply chains provide a clear illustration of modern data principles at work.
Netflix
The company's focus on a "Unified Data Architecture (UDA)" and investment in "real-time distributed graph" systems are prime examples of the Data as a Product principle. By creating a consistent, knowledge-graph-based architecture, Netflix ensures that conceptual domain models are translated into reliable and accessible data schemas across the entire organization, powering everything from content recommendations to production analytics.
LinkedIn's new job search system, which harnesses "advanced LLMs" and "embedding-based retrieval," exemplifies how a scalable data pipeline becomes the engine for advanced, AI-driven product features. This sophisticated infrastructure is capable of deeply understanding user intent to deliver highly personalized results at an unprecedented scale, turning massive datasets into a highly differentiated user experience.
Spotify
Spotify's investment in building an "Analytics Platform" and tools for creating "High-Quality Dashboards at Scale" directly reflects the Self-Serve Data Platform principle. By creating personas for data practitioners and empowering teams across the company with self-service tools, Spotify enables widespread, data-driven decision-making and ensures that insights can be unlocked without creating dependencies on a central team.
Observing how these leaders operate provides a powerful blueprint. The next step is to distill their success into a set of actionable best practices for your own organization.
7.0 Best Practices for Building Your Scalable Data Pipeline
The path to a modern data architecture is guided by a set of core best practices. These principles, drawn from the success of industry leaders and foundational paradigms like the Data Mesh, provide a clear roadmap for reinforcing your digital supply chain and building a resilient data ecosystem.
1. Lead with Business Domains, Not Technology
Your data architecture must be organized around the natural seams of your business. Instead of a single, central IT team owning all data, decentralize ownership to the business units that create and best understand it. This aligns accountability with expertise and makes your data architecture more responsive to business needs.
2. Adopt a "Data as a Product" Mindset
Shift your organizational culture to treat data as a first-class product, not a technical exhaust. This means assigning clear owners to data assets and holding them accountable for quality, discoverability, and usability. Ensure your data is trustworthy and easy for internal customers to consume.
3. Invest in a Self-Serve Platform
Empower your domain teams by providing them with a platform that abstracts away the underlying complexity of data infrastructure. Investing in high-level, automated tools for building, deploying, and managing data pipelines reduces friction, eliminates bottlenecks, and grants teams the autonomy to innovate and deliver value quickly.
4. Establish Federated, Automated Governance
Implement a governance model that enables interoperability without creating a centralized bottleneck. Establish a federated group of domain and platform representatives to define global standards, and then automate the enforcement of these standards through the platform itself. This ensures that autonomy and cohesion can coexist.
5. Choose the Right Tools for the Job
Recognize that a one-size-fits-all approach to data technology is ineffective. Your architecture must support a variety of data stores and processing technologies tailored to specific needs. Differentiate between analytical and transactional workloads, and select the appropriate databases, storage formats, and processing engines for each use case.
These practices are not just about building better technology; they are about creating the organizational and architectural foundation for continuous, data-driven innovation.
8.0 Conclusion: Your Pipeline is the Launchpad for an AI-Powered Future
In the modern enterprise, a scalable, resilient data pipeline is no longer a technical option—it is a strategic necessity. Moving beyond the fragile architectures of the past to embrace a decentralized, product-oriented approach is the definitive way to unlock the true value of an organization's data assets. This shift transforms data from a liability plagued by complexity into the engine of agility, insight, and competitive differentiation.
A modern data pipeline is the prerequisite for the entire AI value chain—from using Machine Learning to find patterns, to deploying Generative AI to act on them, to orchestrating it all with Intelligent Automation to fundamentally reshape business processes. Without a scalable data foundation, these advanced capabilities will remain out of reach.
Ultimately, leaders must view their data pipeline not as a cost to be managed, but as the launchpad for an intelligent, AI-powered future. It is the engine that will power your organization's growth, resilience, and innovation for the next decade and beyond.